14-2. 연관규칙 분석 2
1) 연관규칙 - 데이터 설명 (Groceries)
Groceries data ("arules" package에 탑재되있는 데이터)
- data("Groceries")으로 불러옴
- 실제 식료품점에서 1개월(30일)치의 transaction 데이터
- 9835트랜잭션 / 169 항목
- 밀도가 0.026%라고 되어 있는데, 9335*169 cell 중에서 0.026%의 cell에 거래가 발생해 숫자가 차 있다는 뜻임
- Element(itemset/transaction) length distribution : 하나의 거래 장바구니(row 1개 당)에 item의 개수 별로 몇번의 거래가 있었는지 나타냄
- Groceries data - transaction 데이터
- transaction 9835개
- items수 169개
- Groceries (데이터이름, "arules"package에 탑재되있는 데이터)

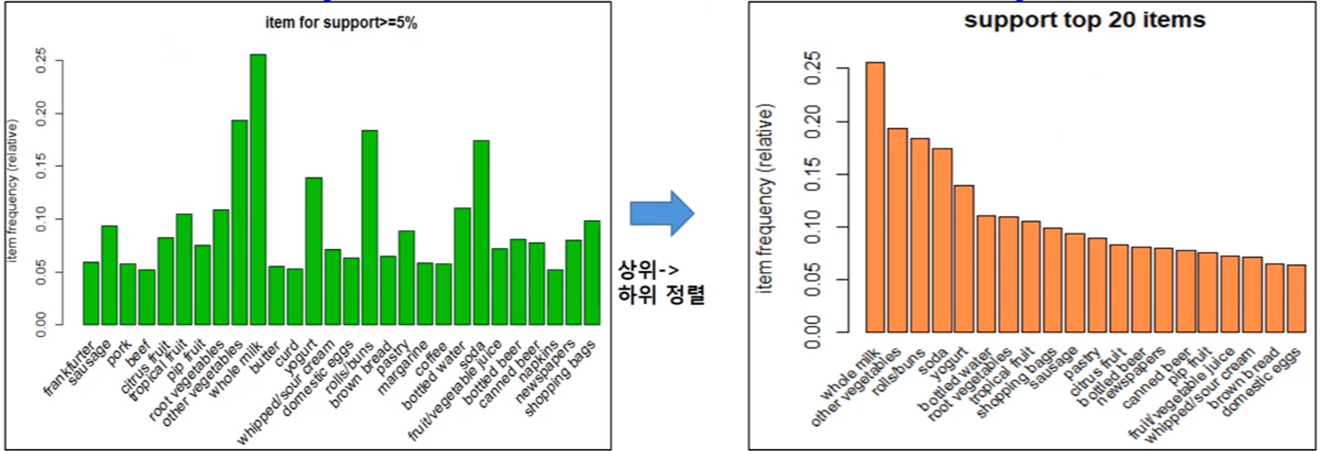
2) 연관규칙 - visualization (지지도)
- 그래프로 표현한 연관규칙 (지지도)
#지지도 5%이상의 item 막대 그래프
itemFrequencyPlot(Groceries,supp=0.05,main="item for support>=5%", col="green", cex=0.8)
#지지도 상위 20개 막대 그래프
itemFrequencyPlot(Groceries,topN=20,main="support top 20 items", col="coral", cex=0.8)
3) 연관규칙 분석결과 - Groceries 데이터
- 연관규칙분석
Grocery_rule<-apriori(data=Groceries, parameter = list(support=0.05, confidence = 0.20, minlen = 2))

- 위의 support, confidence와 length는 minimum값으로 너무 높게 잡으면 연관규칙 분석이 안됨
- 연관규칙 조회 및 평과

- 6개의 rule이 item 2개로 구성되어 있음
- 연관규칙-향상도(Lift)순서로 정렬
inspect(sort(Grocery_rule,by="lift"))
- Sort()함수를 통해 분석가가 보고자 하는 기준으로 정렬하여 보는 것도 가능
- 연관규칙-품목별 연관성 탐색
rule_interest<-subset(Grocery_rule, items %in% c("yogurt","whole milk"))
inspect(rule_interest)
- Sort()함수를 통해 분석가가 보고자하는 기준으로 정렬하여 보는 것도 가능
- Subset()함수를 통해 원하는 item이 포함된 연관규칙만 선별해서 보는 것도 가능
- %in%, %pin%, %ain%을 이용해 다양한 결과 도출
4) 연관규칙 분석결과 저장
- 연관규칙결과를 data.frame으로 저장
Grocery_rule_df<-as(Grocery_rule,"data.frame")
Grocery_rule_df
- 연관규칙결과 저장
write(Grocery_rule, file="Grocery_rule.csv", sep=",", quote=TRUE, row.names=FALSE)
'공부 > R & Python' 카테고리의 다른 글
| 15-1. 주성분 분석과 부분 최소자승법-주성분분석(Principle Component Analysis) (0) | 2020.03.06 |
|---|---|
| 14-3. 로지스틱 회귀분석(Logistic Regression) (0) | 2020.03.05 |
| 14-1. 연관규칙과 로지스틱회귀분석-연관규칙 분석 1(Association Rule Analysis) (0) | 2020.03.05 |
| 13-3. 군집분석 - 비계층적 군집분석 - (0) | 2020.03.05 |
| 13-2. 군집분석 - 계층적 군집분석 - (0) | 2020.03.05 |



