13-3. 군집분석
- 비계층적 군집분석 -
1) 비계층적 군집분석
- 사전에 군집 수 k를 정한 후 각 객체를 k개 중 하나의 군집에 배정

2) k-means 군집분석
- k-means 군집분석은 비계층적 군집분석 중 가장 널리 사용
- k개 군집의 중심좌표를 고려하여 각 객체를 가장 가까운 군집에 배정하는 것을 반복
[단계 0] (초기 객체 선정)
k개 객체 좌표를 초기 군집 중심좌표로 선정
[단계 1] (객체 군집 배정)
각 객체와 k개 중심좌표와의 거리 산출 후, 가장 가까운 군집에 객체 배정
[단계 2] (군집 중심좌표 산출)
새로운 군집의 중심좌표 산출
[단계 3] (수렴 조검 점검)
새로 산출된 중심 좌표값과 이전 좌표값을 비교
수렴 조건 내에 들면 종료, 그렇지 않으면 단계 1 반복
3) k-means 군집분석 예제
- k-means 알고리즘을 적용 (군집 수 k=2라 가정)


4) k-means 군집분석
- 데이터 불러오기 및 군집수 k 결정
dat1<-wages1833
dat1<-na.omit(dat1)
install.packages("factoextra")
library(factoextra)
fviz_nbclust(dat1, kmeans, method = "wss")
- 최적 군집수에 대한 시각화
- 최적값은 "silhoiette", "gap_stat", "wss(그룹내합계제곱)"으로 산출
- 그래프가 완만해지는 지점을 k의 값으로 추정
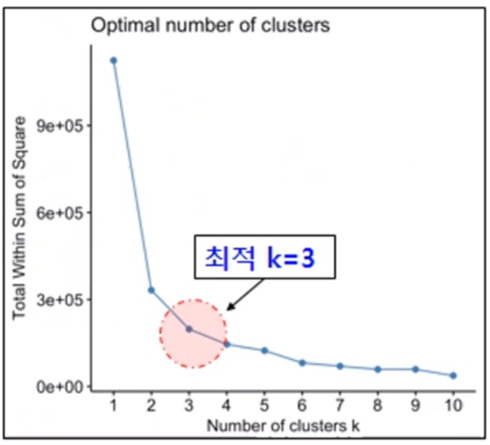
- k-means (k=3)
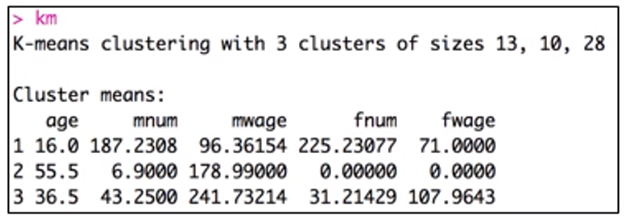
set.seed(123)
km <- kmeans(dat1, 3, nstart = 25)
k=3 / random set의 수 (nstart)
km
fviz_cluster(km, data = dat1,
ellipse.type="convex",
repel = TRUE)
- Kmeans 결과 시각화
- Convex 모양으로 구역표시
- Repel을 통해 관측치 표시

5) k-medoids 군집분석
- K-medoids 군집분석은 각 군집의 대표 객체(medoid)를 고려
- 군집의 대표 객체란, 군집 내 다른 객체들과의 거리가 최소가 되는 객체
- 즉, K-medoids 군집분석은 객체들을 K개의 군집으로 구분하는데,
- 객체와 속하는 군집의 대표 객체와의 거리 총합을 최소로 하는 방법
- PAM 알고리즘 : 모든 객체에 대하여 대표 객체가 변했을 때 발생하는 거리 총합의 변화를 계산.
데이터 수가 많아질수록 연산량이 크게 증가함
- CLARA 알고리즘 : 적절한 수의 객체를 샘플링한 후, PAM 알고리즘을 적용하여 대표 객체 선정
샘플링을 여러 번 한 후 가장 좋은 결과를 택함
편향된 샘플링은 잘못된 결과값을 도출할 수 있음
6) PAM (Partitioning Around Medoids) 알고리즘
- PAM (k=3)
library("cluster")
pam_out <- pam(dat1, 3)
pam_out

table(pam_out$clustering)

fviz_cluster(pam_out, data = dat1,
ellipse.type="convex",
repel = TRUE)

'공부 > R & Python' 카테고리의 다른 글
| 14-2. 연관규칙 분석 2 (0) | 2020.03.05 |
|---|---|
| 14-1. 연관규칙과 로지스틱회귀분석-연관규칙 분석 1(Association Rule Analysis) (0) | 2020.03.05 |
| 13-2. 군집분석 - 계층적 군집분석 - (0) | 2020.03.05 |
| 13-1. 군집분석-군집분석과 유사성척도 (0) | 2020.03.05 |
| 12-3. 랜덤포레스트 (Random Forest) (0) | 2020.03.04 |



