Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
논문 리뷰
Self-Taught Reasoner (STaR)는 CoT(Chain-of-Thought)* 접근 방식을 사용하여 정답으로 이어지는 근거 또는 논리적 단계를 스스로 추론하여 학습하는 방식을 도입했습니다.
*CoT(Chain-of-Thought): 복잡한 문제 해결 과정 중 언어 모델이 중간 단계의 추론 과정이나 'Chain-of-Thought(생각의 연쇄'를 명시적으로 생성하도록 하는 기법
이 논문에서는 STaR에서 확장하여,
언어 모델이 토큰을 생성할 때마다 미래 텍스트를 설명하기 위한 근거를 내부적으로 생성하도록 학습하는 방식인 Quiet-STaR을 제안합니다.
- [Paper] Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
- [Code] Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
* 논문의 아이디어 위주로 러프하게 설명하니 읽기 전 참고 부탁드립니다.
1. Introduction
텍스트 이해의 중요성
텍스트의 의미는 종종 명시적으로 쓰인 내용 사이, 즉 '줄(lines)사이'에 숨어 있으며, 진정한 이해를 위해 이를 파악해야 합니다.
Much of the meaning of text is hidden between the lines: without understanding why statements appear in a document, a reader has only a shallow understanding.
언어 모델의 한계
언어 모델은 상식 추론, 정리 증명, 프로그래밍 등 다양한 작업에서 텍스트의 함축적인 의미를 파악하는 과정에 한계가 있습니다. (추론을 수행하거나 문제를 해결하기 위해 필요한 배경 지식이나 논리적 과정을 내부적으로 생성하는 것에 어려움이 존재합니다.)
Moreover, this has been repeatedly shown to be true for LMs as well in the contexts of tasks ranging from commonsense reasoning to theorem proving to programming.
Quiet-STaR
위 문제를 해결하기 위해 모든 텍스트에 내재된 추론을 언어 모델링 과정에 활용하여 언어 모델 스스로 추론을 학습할 수 있는 방법)을 모색합니다.
We instead ask if reasoning is implicit in all text, why shouldn’t we leverage the task of language modeling to teach reasoning?

- '생각하기(think)' 단계에서 근거 또는 논리를 토큰별로 병렬 생성하고,
- 이를 '말하기(talk)' 단계에서 예측에 활용(혼합하여 생성)하며,
- '배우기(learn)' 단계에서 강화학습(REINFORCE)으로 어떤 근거가 유용했는지 판단하고 학습하는
Quiet-STaR 방법을 제안합니다.
2. Related Work & Problem Statement
Reasoning in Language Models (언어 모델에서의 추론)
언어 모델을 시용해 어려운 작업을 해결하기 위한 여러 접근 방식을 소개합니다.
(논문 2.1 Reasoning in Language Models 세션 참고)
Training Language Models to Reason (언어 모델을 근거에 따라 훈련)
언어 모델을 추론하도록 학습시키는 다른 접근법으로 이전에 추론 흔적이나 추론과 같은 데이터에 언어 모델을 학습하는 방법이 존재합니다.
그러나 수동 주석이 필요하고 언어 모델에 비정형적인 추론 분포를 생성하게 만들며(주석자에 따라 민감함), 비용, 확장성 측면에서의 단점이 있습니다.
One direction that researchers have used to train language models to reason or improve their reasoning is training the language model on mined reasoning traces or reasoning-like data
(Rajani et al., 2019; Wei et al., 2021a; Lewkowycz et al., 2022; Chung et al., 2022; Gunasekar et al., 2023).
...
It requires either manual annotation, which is sensitive to the capability of the annotators and is off-policy for the language model (i.e., the distribution of reasoning is not text that the language model would otherwise likely have generated). This approach is also expensive, difficult to scale, and provides no clear path to solving problems harder than those that the annotators are capable of solving.
Meta-tokens
특정 기능을 수행하기 위해 최적화된 사용자 정의 토큰들이 신경망 컨텍스트에서 유용하다는 것과 관련된 연구들을 소개합니다.
(논문 2.3 Meta-tokens 세션 참고)
Problem Statement
언어 모델이 각 관찰된 토큰 쌍 사이에 'rationale(근거)' 변수를 도입하는 새로운 방법을 제안합니다.
중간 생각(또는 근거)를 생성할 수 있는 능력을 갖춘 매개 변수 θ가 있는 언어 모델을 최적화하여,
모델이 텍스트의 나머지 부분을 더 정확하게 예측할 수 있도록 합니다.
언어 모델이 문자열의 분포를 정확하게 모델링하는 경우에는 이점을 제공하지 않을 수도 있습니다.
그러나 실제 선행 연구에서 추론 작업의 중간 근거는 언어 모델의 성능을 개선하는 데 도움이 됩니다.
In this work, we introduce an auxiliary ‘rationale’ variable between each pair of observed tokens of the sequence. We then aim to optimize a language model with parameters θ with the capacity to generate intermediate thoughts (or rationales) such that
θ* = arg max θ Ex[logpθ(xi:n|x0:i rationaleθ(x0:i))]
Note that in principle this provides no advantage over an optimal language model that already correctly models the language’s distribution over strings. Yet in practice, extensive prior work has shown that language models benefit from intermediate rationales on reasoning tasks.
3. Quiet-STaR
Quiet-STaR은 Parallel Generation(병렬 생성 , think), "Mixing" Head("혼합" 헤드, talk), Optimizing Rationale Generation(근거 생성 최적화, learn) 단계로 동작합니다. (Figure 1 참고)
3-1. Parallel rationale generation (병렬 근거 생성, think)
병렬로 근거 후보를 만들고, 각 근거의 시작과 끝을 표현하기 위해 <|startofthought|> and <|endofthought|> 토큰을 사용합니다.
이는 계산적으로 실현 가능하며, 언어 모델의 추론 경로를 활용하여 모든 입력 토큰에 대한 다음 토큰의 확률 분포를 생성합니다.

In parallel across n tokens xi in an input sequence x0:n, we generate r rationales of length t: ci = (ci1 ... cit) resulting in n × r rationale candidates. We insert learned <|startofthought|> and <|endofthought|> tokens to mark each rationale’s start and end.
3-2. Mixing post-rationale and base predictions (이후 근거와 기본 예측 혼합, talk)
각각의 근거 이후 hidden state 출력으로, '혼합 헤드'를 훈련합니다. post-rationale 다음 토큰의 예측 logits이 얼마나 포함되어야 하는지 결정하는 Shallow MLP를 사용합니다.
이는 언어 모델이 근거를 도입함으로써 발생할 수 있는 분포 변화를 완화할 수 있습니다.
From the hidden state output after each rationale, we train a 'mixing head' – a shallow MLP producing a weight determining how much the post-rationale next-token predicted logits should be incorporated compared to the base language model predicted logits. This approach eases distribution shift early in finetuning due to introducing rationales.
3-3. Optimizing rationale generation (근거 생성 최적화, learn)
REINFORCE 알고리즘을 사용하여 근거 생성 매개변수(시작/종료 토큰 및 LM 가중치)를 최적화합니다. (=근거의 유용성에 따라 그 확률을 최적화합니다.)
We optimize the rationale generation parameters (start/end tokens and LM weights) to increase the likelihood of rationales that make future text more probable. We use REINFORCE to provide a learning signal to rationales based on their impact on future-token prediction.
4. Experiments and Results
Downstream Performance
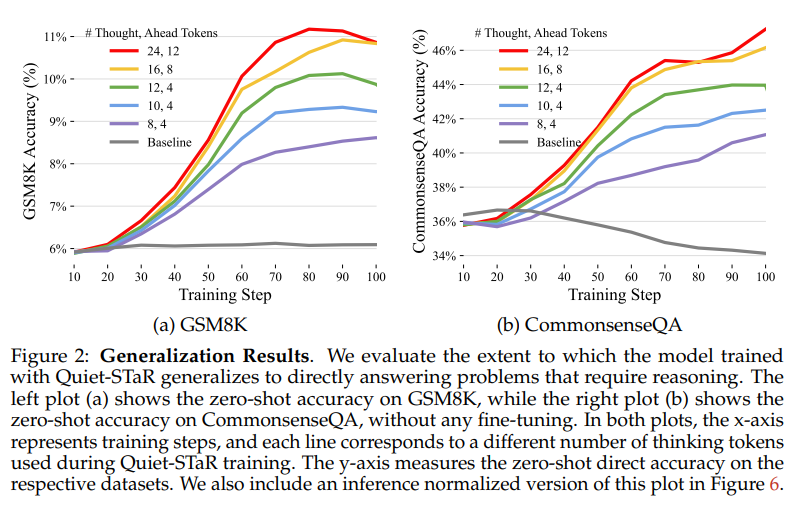
Quiet-STaR는 CommonsenseQA와 GSM8K와 같이 추론이 필요한 데이터셋에서 언어 모델의 예측 능력을 베이스 모델보다 10.9%, 5% 향상시켰습니다.
On CommonsenseQA, we find that Quiet-STaR improves performance by 10.9% compared to the base language model
...
Similarly, on GSM8K, Quiet-STaR results in a 5.0% boost over the base model.
Improvement Distribution

Quiet-STaR 훈련이 임의의 토큰을 예측하는 능력은 크게 향상시키지는 않지만, 어려운 토큰을 예측하는 능력에 있어서 일부 개선이 나타납니다.
We find that on average, there is little improvement in the LM’s ability to predict arbitrary tokens. But when we visualize the distribution of relative improvements, there is a disproportionate improvement on more difficult tokens.
Quiet-STaR and Chain-of-Thought
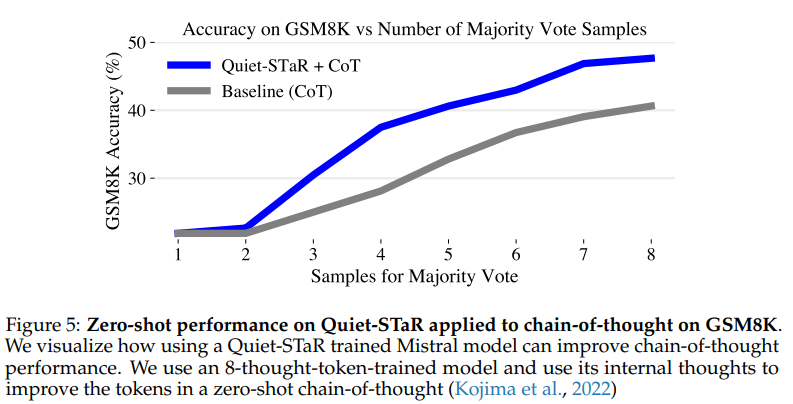
8개의 샘플(cot-maj@8)에 대한 정확도는 Quiet-STaR을 사용하면 40.6%에서 47.7%로 증가합니다.
Our experiments indicate that internal rationales allow the model to generate more structured and coherent chains of thought... The majority vote accuracy over 8 samples (cot-maj@8) increases from 40.6% to 47.7% with Quiet-STaR.
5. Limitations & Conclusion
Limitations
Quiet-STaR은 추론 학습을 위한 새로운 프레임워크를 제안하여 meta-learning(메타러닝) 문제에 대한 해결책을 탐색했지만, 일부 한계가 존재합니다.
- 학습 데이터와 추론 과정의 단순화: 모델이 언어 이해와 추론을 개선하기 위해 내부적으로 '생각'을 생성하지만, 이 과정에서 실제 인간의 추론 과정이나 다양한 지식 소스를 완벽하게 반영하기보다는, 간소화된 형태로 모델링되었습니다. (실제 인간의 사고 방식과 차이 존재)
- 모델 크기 제한: 7억 개의 파라미터를 가진 모델에만 적용되었으며, 더 크거나 작은 모델에서의 효과는 아직 확인되지 않았습니다.
- 컴퓨팅 자원 효율 제한: Quiet-STaR는 모든 추가 토큰 생성에 상당한 계산 오버헤드를 수반하며, 이는 학습과 추론 과정에서의 효율성을 제한할 수 있습니다.
Conclusion
- Quiet-STaR는 언어 모델이 일반적이고 확장 가능한 방식으로 추론을 학습할 수 있는 방향을 제시합니다.
- Downstream에서 언어 모델의 추론 능력 향상과 의미 있는 근거 생성을 통해 접근 방식의 가능성을 입증합니다.
- 향후 언어 모델과 인간과 같은 추론 능력 사이의 간극을 좁히는 데 기여할 수 있습니다.
'IT > 인공지능' 카테고리의 다른 글
| [LLM] ReALM: Reference Resolution As Language Modeling 논문 리뷰 (0) | 2024.04.21 |
|---|---|
| [LLM] Social Skill Training with Large Language Models 논문 리뷰 (0) | 2024.04.10 |
| [TTS] 외래어와 수사를 고려한 한국어 텍스트 발음 변환 (1) | 2024.03.24 |
| [RAG] RAFT: Adapting Language Model to Domain Specific RAG 논문 리뷰 (0) | 2024.03.19 |
| [생성형AI][LLM] vLLM: LLM 추론 및 배포 최적화 라이브러리 (1) | 2024.03.12 |



