[생성형AI][LLM] vLLM: LLM 추론 및 배포 최적화 라이브러리
1. vLLM이란?
Attention Key와 Value을 효과적으로 관리하는 새로운 Attention 알고리즘인 PagedAttention을 활용하여 높은 처리량을 보여주는 LLM 서비스입니다.
- Efficient Memory Management for Large Language Model Serving with PagedAttention 논문을 기반으로 합니다.
- 비슷한 LLM 추론 및 배포 서비스로 HuggingFace의 TGI(Text Generation Inference)가 있습니다.
- vLLM 블로그와 Github 저장소에서 vLLM에 관한 내용과 코드를 확인할 수 있습니다.
2. 기존 방식의 한계점
LLM 추론 방식의 특징
LLM의 핵심 구성요소인 자기회귀 트랜스포머(Autoregressive Transformer)는 입력(프롬프트)을 기반으로 하나씩 단어(토큰)을 생성합니다. 모델은 입력과 지금까지 생성된 출력의 토큰 시퀀스에 기반하여 새로운 토큰을 생성하는 방식으로 작동합니다. 각 요청에 대해 이 과정은 비용이 많이 들며, 모델이 종료 토큰을 출력할 때까지 반복됩니다.

이 순차적인 생성 과정에서 모델은 각 단계에서 한 토큰을 입력으로 받아들이고, 모든 이전 토큰의 키(key) 및 값(value) 벡터를 사용하여 다음 토큰의 확률을 계산합니다.
- Query, Key, Value 간단한 설명
- Query: 쿼리는 현재 단어를 나타내며, 다른 모든 단어(그들의 키를 사용하여)와 비교 점수를 매깁니다. 우리는 현재 처리하고 있는 토큰의 쿼리만을 고려합니다.
- Key: 키 벡터는 세그먼트 내 모든 단어에 대한 레이블과 같습니다. 이것들은 우리가 관련 단어를 찾기 위해 비교 대상으로 삼는 것들입니다.
- Value: 값 벡터는 실제 단어 표현입니다. 각 단어의 관련성을 점수화한 후, 이 값들을 합산하여 현재 단어를 나타냅니다.
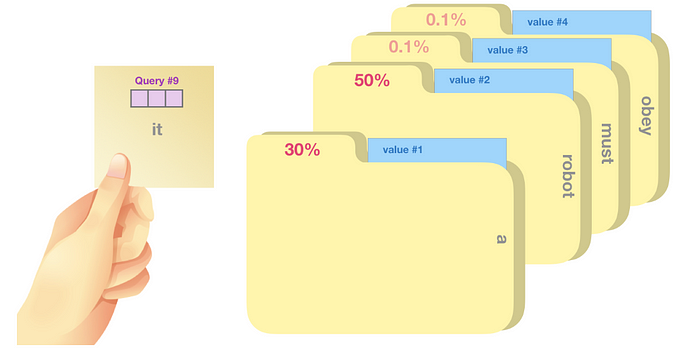
- Q(query), K(key), V(value)라는 값을 통해서, sentence를 구성하는 단어들 간의 연관성을 파악합니다.
- Q : 디코더의 이전 레이어 hidden state, 영향을 받는 디코더의 토큰
- K : 인코더의 output state, 영향을 주는 인코더의 토큰들
- V : 인코더의 output state, 그 영향에 대한 가중치가 곱해질 인코더 토큰들
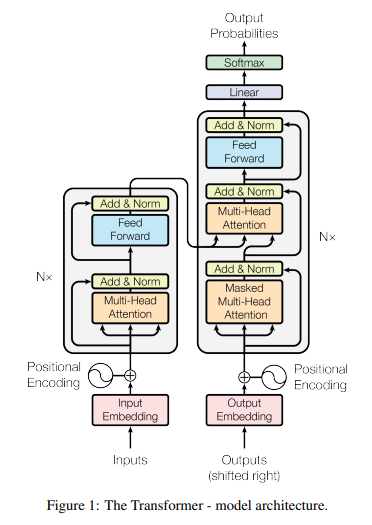

이전 토큰에서 생성된 키 및 값 벡터는 KV 캐시에 저장되며, 각 반복 단계에서 새로운 키 및 값 벡터만이 계산됩니다. 모델이 지정한 최대 길이에 도달하거나 종료 토큰을 출력할 때까지 계속됩니다.

그러나, 이 순차적인 생성 과정은 GPU의 계산 능력을 충분히 활용하지 못하며 Serving 처리량을 제한하게 됩니다.
비효율적인 KV 캐시 메모리 관리
기존 LLM 서빙 시스템들은 KV 캐시를 연속적인 메모리 공간에 저장하는 방식을 사용합니다. 대부분의 딥 러닝 프레임워크에서 텐서를 연속적인 메모리에 저장해야 하기 때문입니다. 하지만, LLM의 특성상 출력 길이가 예측 불가능하며 동적으로 변화하기 때문에, 3가지 주요 메모리 낭비 문제를 초래합니다.

- 내부 메모리 단편화(Internal Memory Fragmentation): 기존 시스템들은 요청의 최대 길이에 해당하는 메모리를 사전에 할당합니다. 이는 실제 요청 길이가 최대 길이보다 훨씬 짧을 경우 심각한 내부 메모리 단편화를 초래할 수 있습니다. 예를 들어, 요청의 실제 길이가 최대 길이의 절반만 필요한 경우, 나머지 절반의 메모리는 사용되지 않고 낭비됩니다.
- 외부 메모리 단편화(External Memory Fragmentation): 서로 다른 요청 길이 때문에 외부 메모리 단편화가 발생하여, 메모리가 낭비됩니다.
- 메모리 예약(Reserved Memory)으로 인한 비효율: 요청마다 최대 길이에 해당하는 메모리를 예약하게 되면, 실제로는 사용되지 않는 메모리가 발생합니다. 이는 다른 요청이 그 메모리를 사용할 수 없게 만들어 전체적인 메모리 활용도를 낮추고, 배치 크기와 처리량을 제한합니다.
메모리 공유 불가능
기존 LLM 서비스는 병렬 디코딩 알고리즘(Parallel sampling, beam search 등)을 사용하기 때문에, KV 캐시가 요청마다 별도의 연속적인 공간에 저장되므로, 메모리 공유를 실현할 수 없습니다.
✅ 문제점
기존의 LLM 서빙 시스템이 KV 캐시 메모리를 효율적으로 관리하지 못합니다.
✅ 제안점
운영 체제의 가상 메모리 및 페이징 기술에서 영감을 받은 PagedAttention으로 KV 캐시 메모리의 낭비를 줄이고, 요청 간 및 요청 내에서의 유연한 공유를 가능하게 하여 LLM 서빙 시스템의 처리량을 향상시킬 수 있습니다.
3. vLLM 원리 및 구조
vLLM(very Large Language Model)는 LLM 서빙을 위해 특별히 설계된 고성능 분산 시스템 아키텍처를 보여줍니다. 이 시스템은 특히 메모리 관리와 관련하여, 기존 시스템의 한계를 극복하고, 대규모 언어 모델의 효율적인 서빙을 가능하게 하는 여러 중요한 구성 요소를 포함하고 있습니다.

중앙 집중식 스케줄러(Centralized Scheduler)
모든 요청과 GPU 워커들 간의 조정을 담당합니다. 스케줄러는 요청을 받아 처리 우선 순위를 결정하고, 어떤 GPU 워커가 해당 요청을 처리할지를 결정합니다. 요청 간의 의존성을 관리하고, 시스템 전체의 메모리 사용을 최적화합니다.
GPU 워커(GPU Workers)
실제로 언어 모델의 추론 작업을 수행하는 컴포넌트입니다. 각 워커는 독립적으로 작동하면서, 스케줄러로부터 받은 지시에 따라 특정 요청을 처리합니다. 워커들은 모델 파라미터를 공유하며, PagedAttention 메커니즘을 사용하여 메모리 접근을 최적화합니다.
vLLM은 분산 환경에서 Megatron-LM 스타일의 텐서 모델 병렬 처리 전략을 지원합니다. 각 GPU 워커는 Megatron-LM 스타일로 분할된 모델의 일부분을 할당받아 처리합니다. 이는 모델의 선형 레이어가 여러 GPU에 걸쳐 분할되어 있음을 의미하며, 각 워커는 할당받은 부분의 연산을 담당합니다.
모델 병렬 처리에서 각 GPU 워커는 다른 워커들과 중간 결과를 동기화해야 합니다. vLLM에서는 all-reduce 연산*을 사용하여 이러한 동기화를 수행하며, 각 워커의 중간 결과를 통합하여 최종 결과를 도출합니다.
*all-reduce 연산: 병렬 컴퓨팅 환경에서 사용되는 데이터 동기화 방법. 분산 시스템 내의 여러 노드 또는 프로세스 간에 데이터를 집계하고, 그 결과를 모든 노드 또는 프로세스에 다시 분배하는 과정
PagedAttention 메커니즘
기존의 연속적인 메모리 할당 방식 대신, KV 캐시를 더 작은 블록으로 나누고 이들을 비연속적으로 할당하는 방식을 사용합니다. 이는 메모리 단편화를 크게 줄이고, 필요한 메모리만 할당하여 전체 메모리 사용 효율을 높입니다.
OS 페이징 기법에서의 매핑
- 블록 → 페이지
- 토큰 → 바이트
- 시퀀스 → 프로세스
KV 캐시는 블록으로 분할되며, 블록은 메모리 공간에서 연속적이지 않아도 됩니다. 블록은 메모리에서 연속적일 필요가 없기 때문에 OS의 가상 메모리와 같은 효율적인 방식으로 Key와 Value을 관리할 수 있습니다

- PagedAttention 기반 요청 생성 프로세스
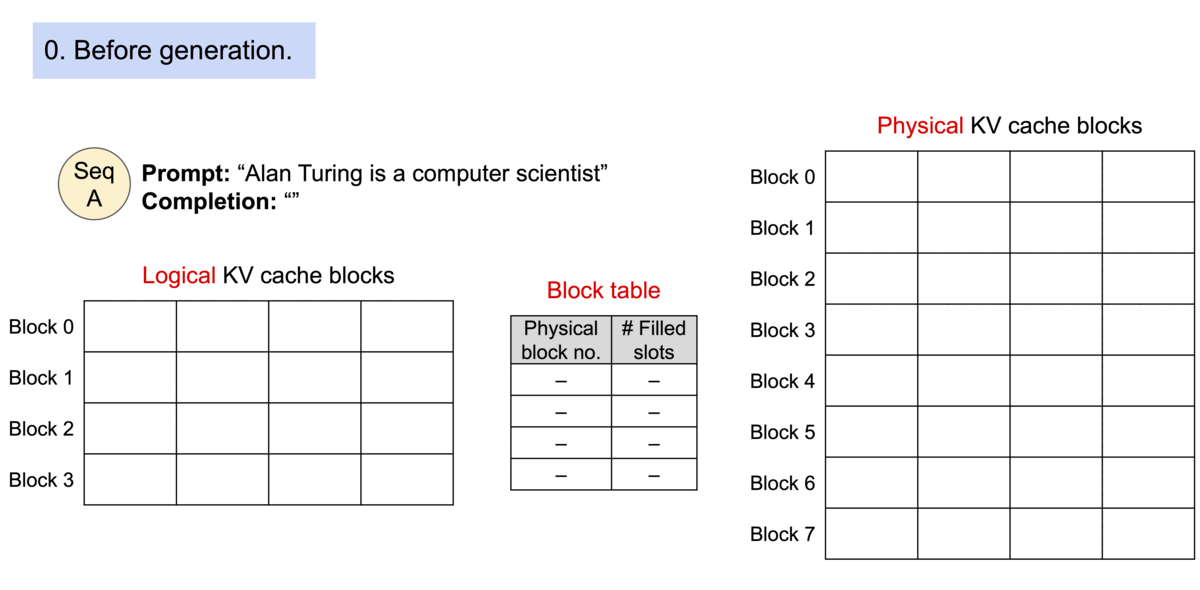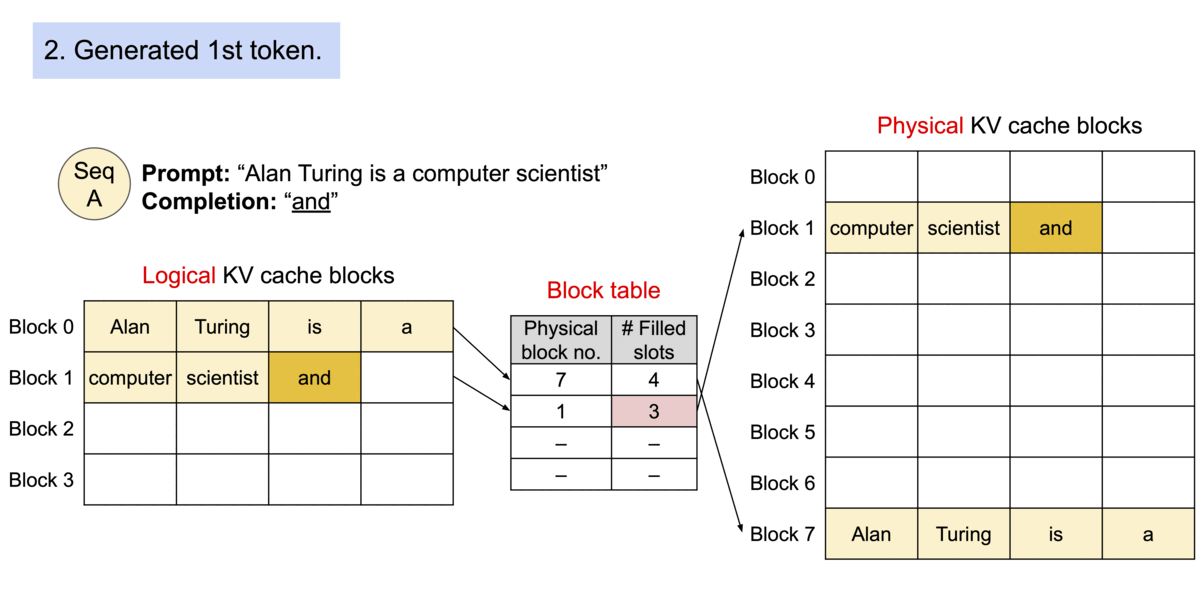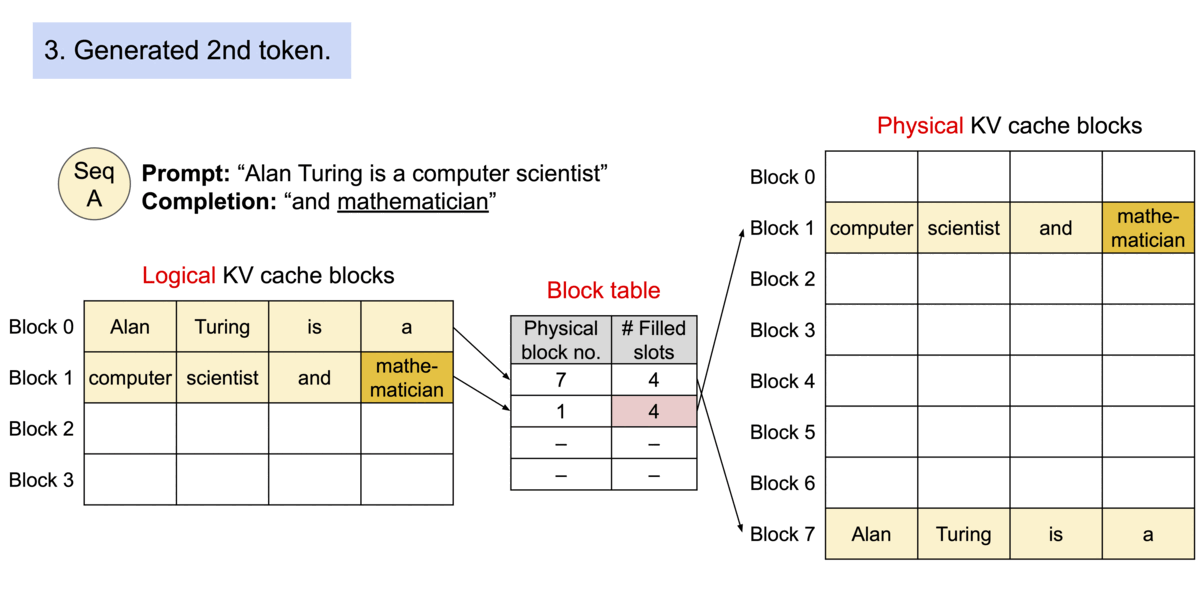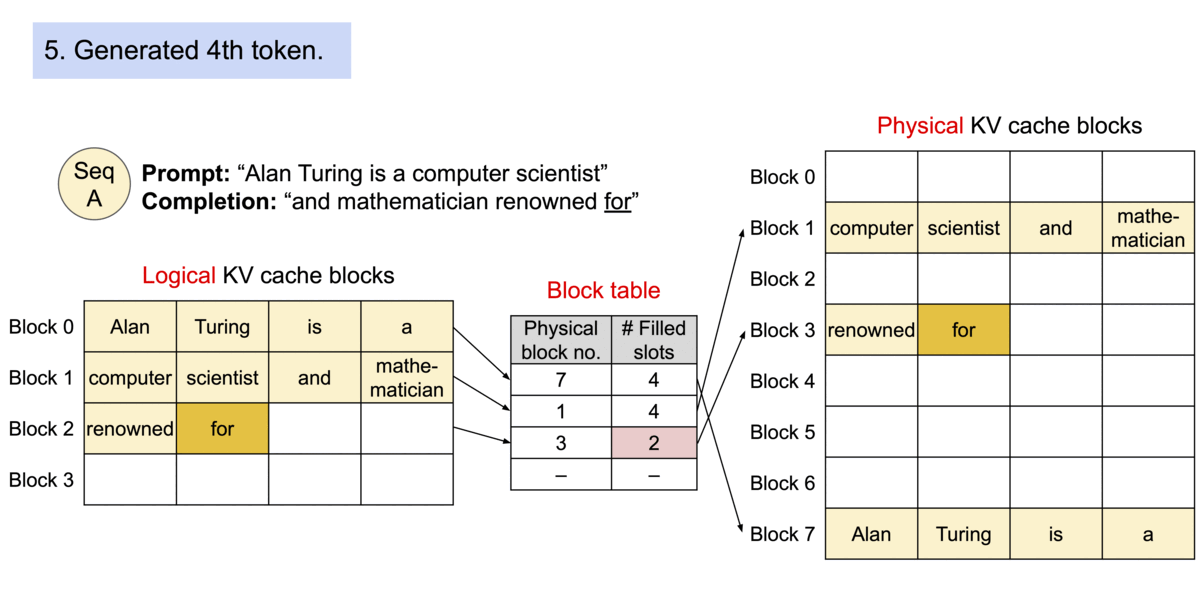
https://blog.vllm.ai/2023/06/20/vllm.html - PagedAttention 기반 메모리 공유
병렬 샘플링에서는 동일한 프롬프트에서 여러 출력 시퀀스가 생성되며, 프롬프트에 대한 계산 및 메모리를 출력 시퀀스 간에 공유할 수 있습니다.
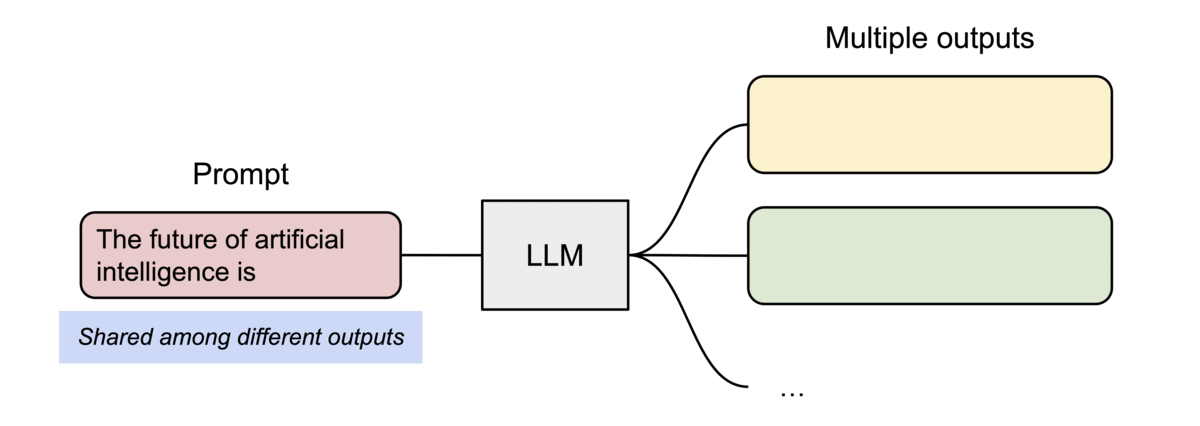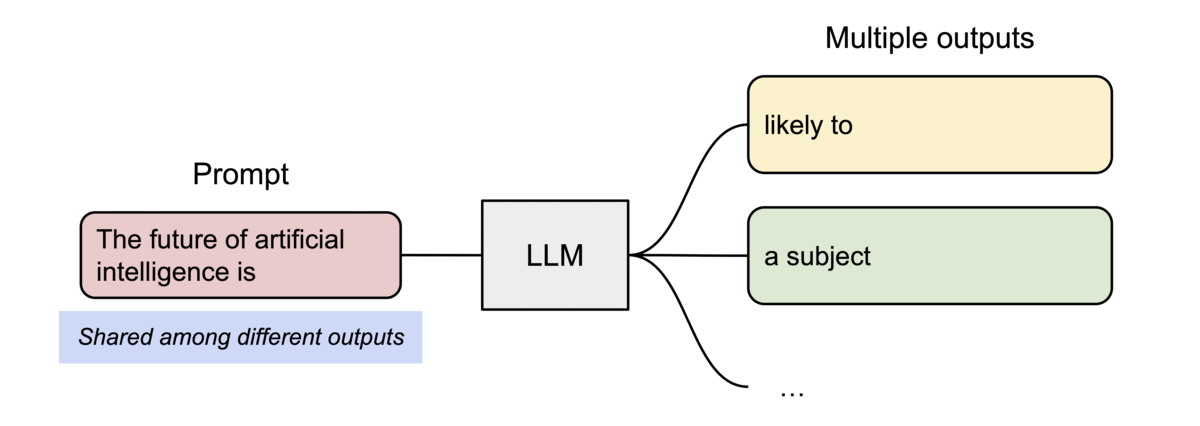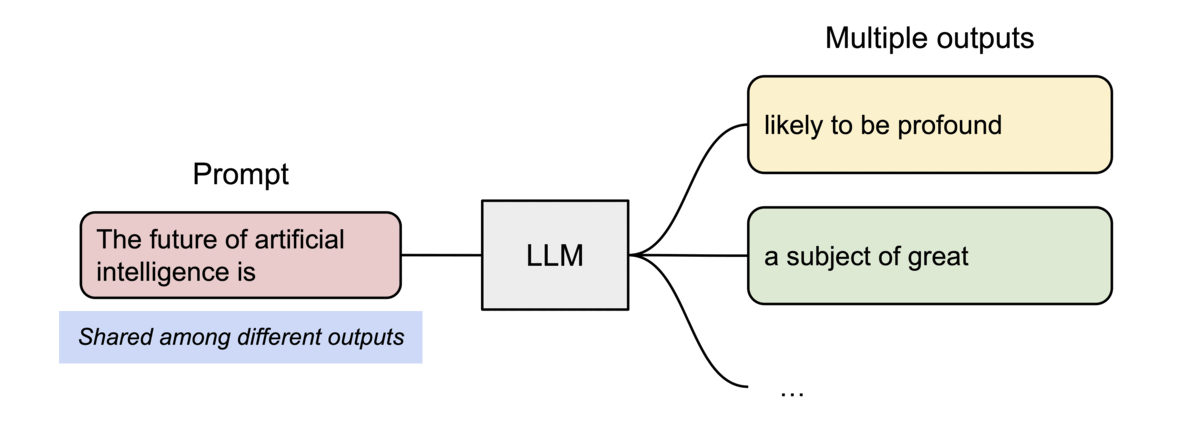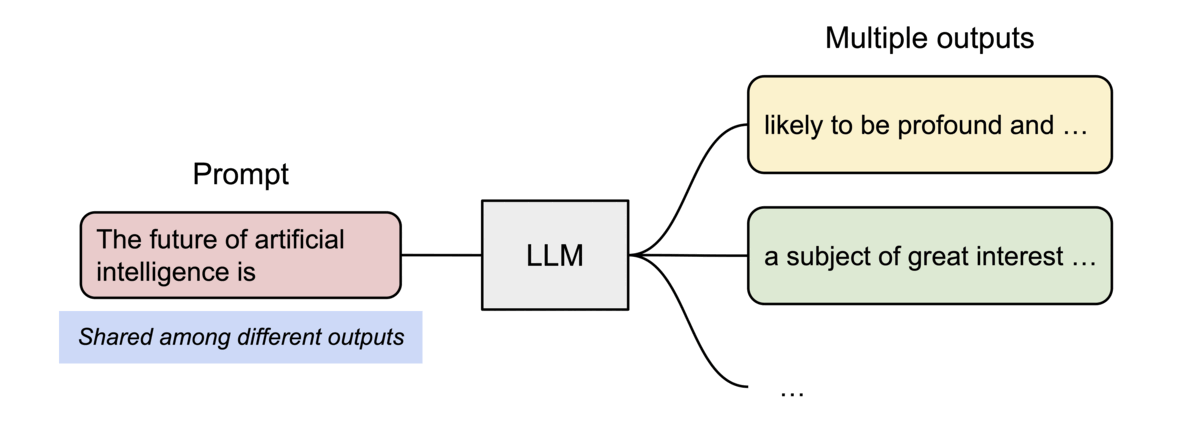
- Beam Search에서 공통된 시퀀스 부분에 대한 KV 캐시를 여러 후보군이 공유할 수 있습니다.

Efficient Memory Management for Large Language Model Serving with PagedAttention - 여러 출력을 샘플링하는 요청 생성 프로세스
- OS의 Copy-on-Write: 수정 가능한 자원에 대한 복제 또는 복사 작업을 효율적으로 구현하기 위해 사용되는 자원 관리 기술, fork()와 유사
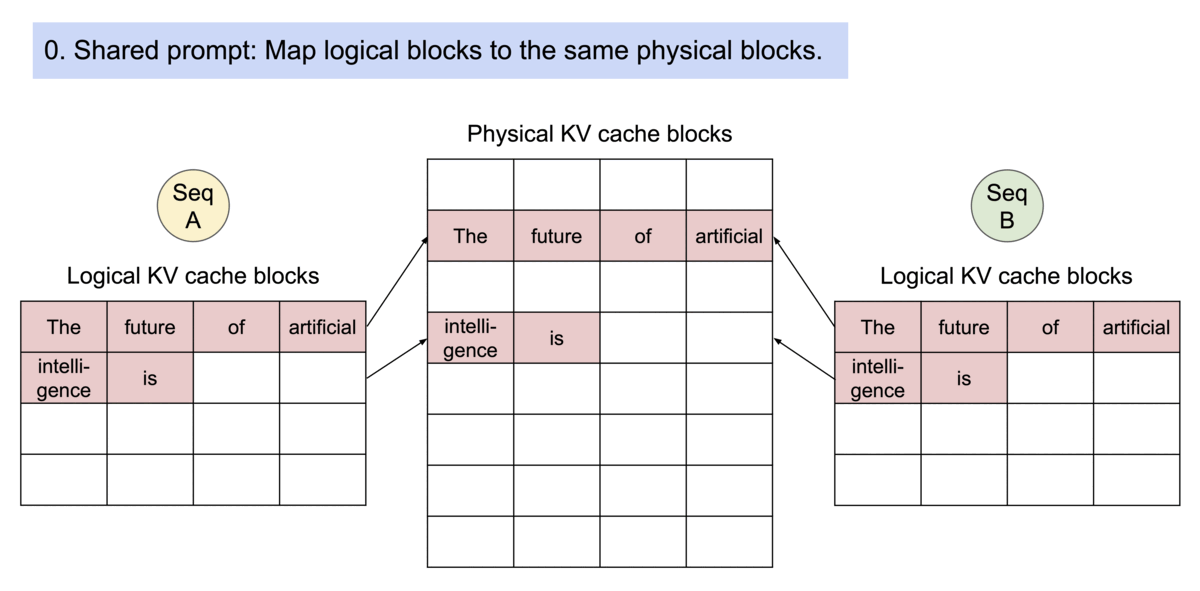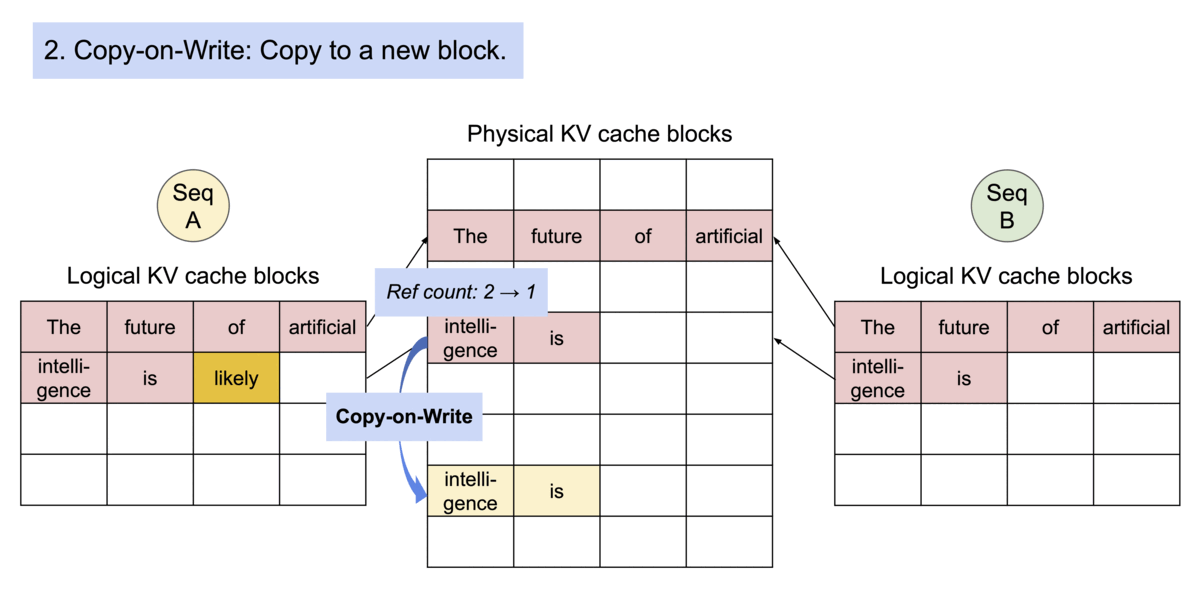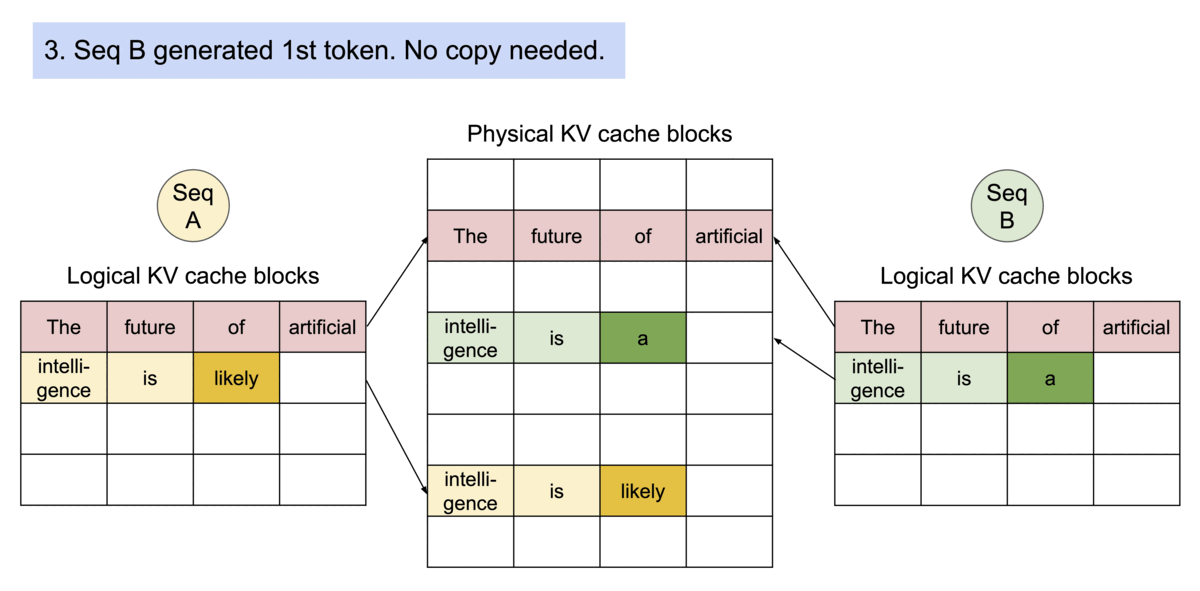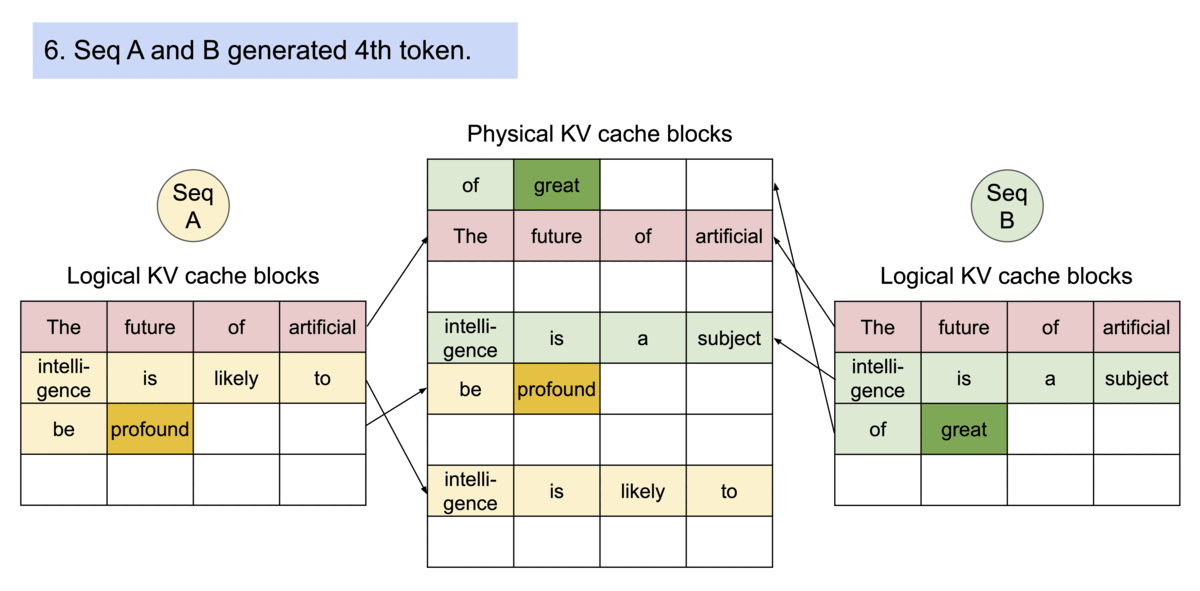
vLLM에서는 모든 요청에 대해 선입선출(FCFS) 스케줄링 정책을 채택하여 공정성을 보장하고 기아 상태를 방지합니다.
KV 캐시 매니저(KV Cache Manager)
KV 캐시 매니저는 각 요청의 KV 캐시 메모리를 관리합니다.
- 동적 메모리 할당: KV 캐시 매니저는 각 요청이 처리되는 동안 필요한 메모리를 동적으로 할당합니다. 요청의 크기나 상태가 변경되면, 이에 맞추어 필요한 메모리를 추가로 할당하거나 불필요한 메모리를 해제합니다.
- 메모리 선점과 복구: 시스템에 자원이 부족할 때, KV 캐시 매니저는 메모리를 가장 많이 사용하는 요청이나 가장 최근에 처리된 요청부터 메모리를 선점합니다. 선점된 요청이 다시 활성화될 때는 해당 요청의 KV 캐시를 재구성합니다. 스와핑(swap) 또는 재계산(recomputation) 방법을 사용할 수 있습니다. (스와핑 및 재계산 과정에서 CPU RAM과 GPU RAM을 활용합니다. - CPU Block Allocator, GPU Block Allocator)
- 자원 사용 최적화: 여러 요청 간에 KV 캐시를 공유할 수 있는 경우, KV 캐시 매니저는 이를 통해 메모리 사용을 최적화합니다. 비슷한 요청이나 반복되는 패턴을 가진 요청에서 유용합니다.
블록 테이블(Block Tables)
블록 테이블은 논리적인 KV 블록과 실제 메모리 상의 위치 사이의 매핑을 관리합니다.
- 메모리 매핑 관리: 각 요청에 대한 KV 캐시 블록이 어디에 저장되어 있는지 추적합니다. 요청이 처리되는 동안 블록 테이블을 통해 필요한 데이터의 위치를 찾아낼 수 있습니다.
- 메모리 접근 최적화: 블록 테이블을 활용하여 GPU 워커들의 메모리 접근을 최적화할 수 있습니다. 메모리가 비연속적으로 할당되어 있더라도 빠르게 데이터에 접근할 수 있습니다.
- 메모리 선점 및 복구 지원: 요청의 메모리가 선점되었을 때, 해당 요청의 블록 테이블 정보도 함께 저장되고, 관리됩니다. 요청이 재활성화되면, 블록 테이블을 통해 기존의 메모리 구조를 복구할 수 있습니다.
4. vLLM 성능
- 각 요청이 하나의 출력 요청: HF보다 14배~24배 더 높은 처리량, TGI보다 2.2배~2.5배 더 높은 처리량
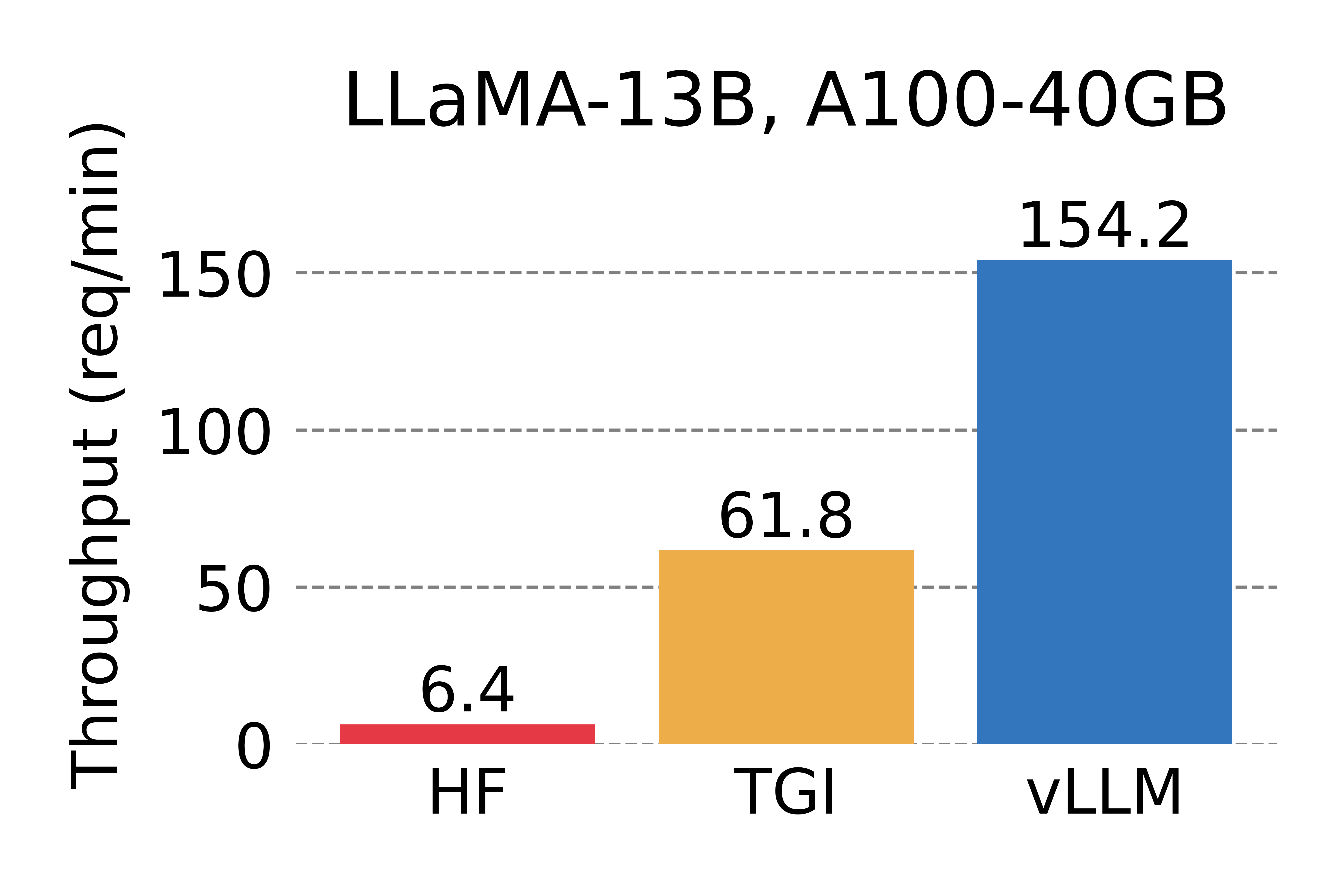
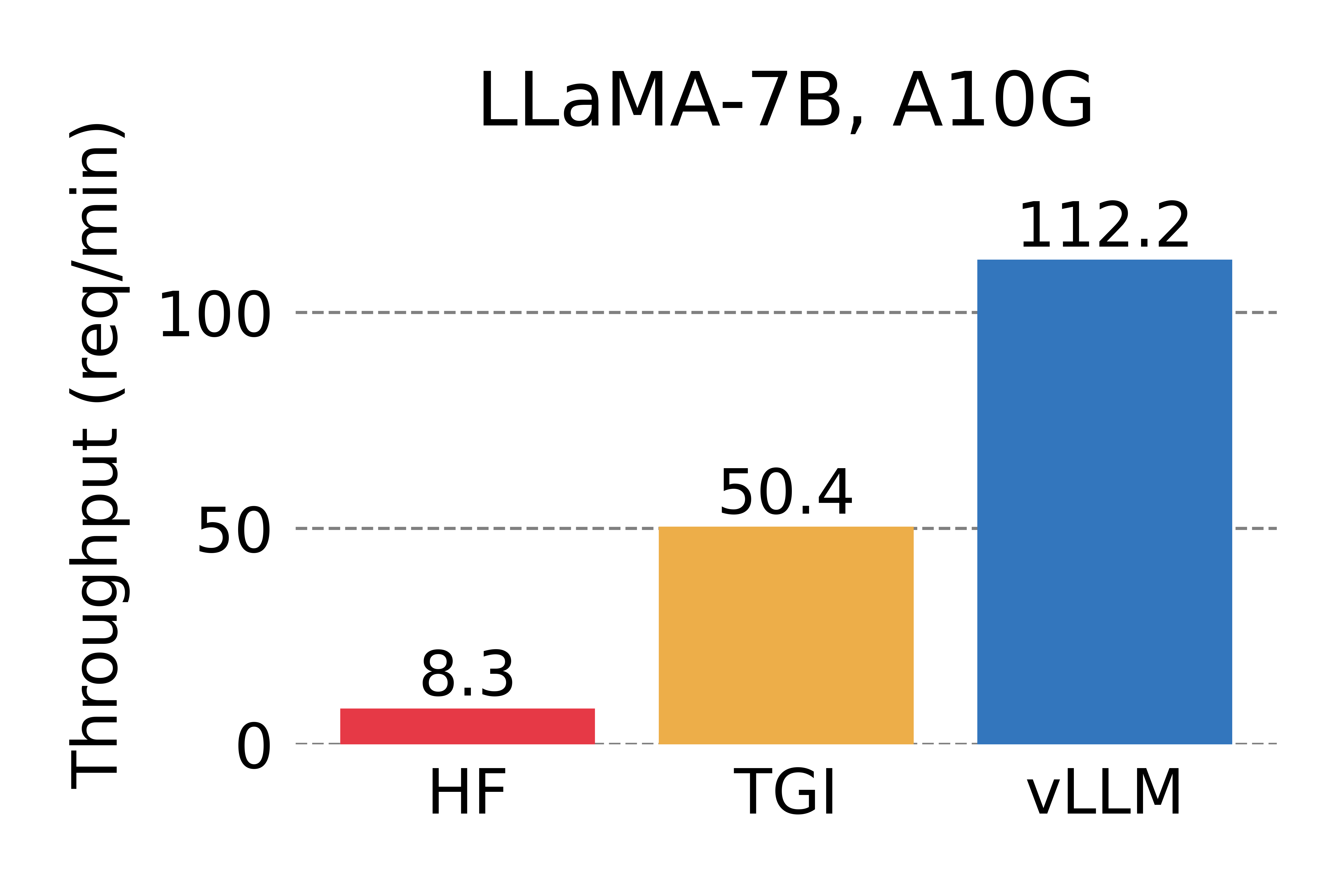
- 각 요청이 3개의 병렬 출력 요청: HF보다 8.5배~15배 더 높은 처리량, TGI보다 3.3배~3.5배 더 높은 처리량


현재 HuggingFace의 TGI도 Flash Attention과 Paged Attention를 모두 사용하고 있습니다.
'IT > 인공지능' 카테고리의 다른 글
| [TTS] 외래어와 수사를 고려한 한국어 텍스트 발음 변환 (1) | 2024.03.24 |
|---|---|
| [RAG] RAFT: Adapting Language Model to Domain Specific RAG 논문 리뷰 (0) | 2024.03.19 |
| [GPU] RAPIDS: 대규모 데이터 세트 분석을 위한 GPU 가속 프레임워크 (0) | 2024.02.27 |
| [생성형AI][LLM] RAG 기반 기술문서 QA Gemma 모델 (Hugging Face) (0) | 2024.02.24 |
| [생성형AI][LLM] Gemma 모델 파인튜닝 (Hugging Face) (3) | 2024.02.24 |


