16. 딥러닝과 텍스트 마이닝
16-1. Neural Network
1) Concepts
- 인공신경망은 기계학습(Machine Learning)의 통계적 학습 알고리즘 중 하나
- 컴퓨터 비전, 자연어 처리, 음성 인식 등의 영역에서 활발하게 사용됨

- 신경망 모델은 (Neural Network)은 Percoptron을 한 단위로 하는 네트워크를 구축하여, 인간의 신경세포(Neuron)과 유사한 기능을 하도록 제안되었음

2) Perceptron - Single Layer
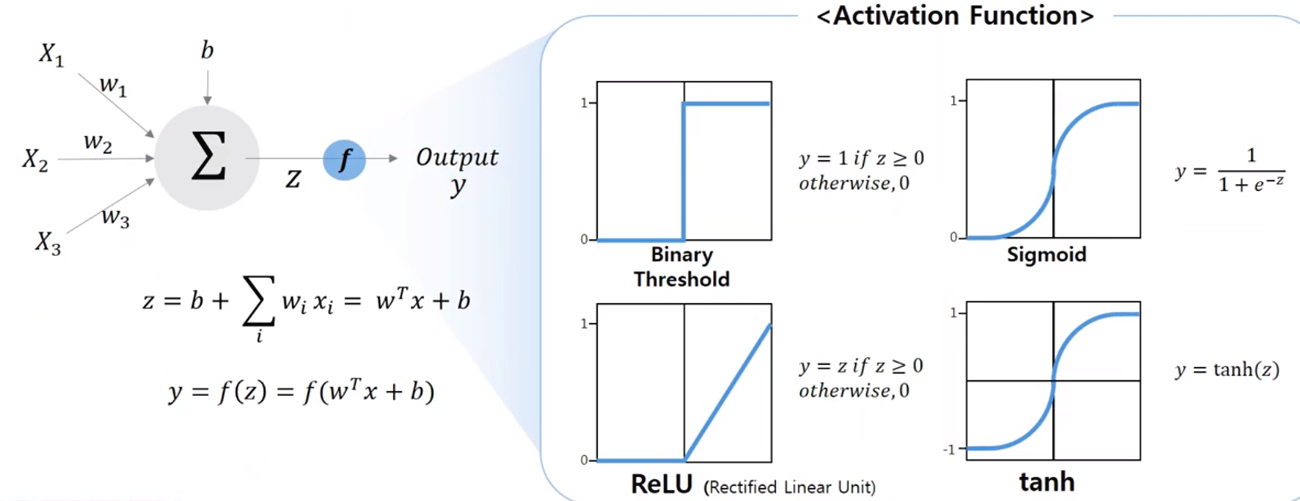
- 하나의 Percoptron은 단순하게 다수의 입력과 가중치의 선형 결합을 계산하는 역할을 수행
- Activation 함수에 따라 선형결합으로 생성되는 출력의 값이 결정됨
3) Multi-layer perceptron
- Perceptron으로 구성된 Single Layer들이 Multi-layer를 만듬
- Input layer과 Output layer 사이에는 Hidden layer가 존재하여 Non-linear transformation을 수행
- Output layer에서 Softmax 함수를 통해 가장 큰 값을 손쉽게 알 수 있음
- Exponential 함수로 인해 항상 양수의 결과치가 도출되고 이를 통해 확률값을 도출함

4) Neural Network 수행
- 신경망 모델 생성을 위한 패키지 : mxnet
- iris 데이터를 이용
install.packages("https://github.com/jeremiedb/mxnet_winbin/raw/master/mxnet.zip",repos = NULL)
library(mxnet)
iris[,5] = as.numeric(iris[,5])-1
table(Species)
head(iris, n=10)

Species을 Label로 활용, 각 종별로 0, 1, 2의 숫자로 변화
- 학습데이터와 검증데이터
set.seed(1000)
N<-nrow(iris)
tr.idx<-sample(1:N, size=N*2/3, replace=FALSE)
train<-data.matrix(iris[tr.idx,])
test<-data.matrix(iris[-tr.idx,])
학습데이터 : 2/3 (100개)
검증데이터 : 1/3 (50개)
train_feature<-train[,-5]
trainLabels<-train[,5]
test_feature<-test[,-5]
testLabels <-test[,5]
Label은 5번째 열에 위치...
각 객체별 Feature와 Label로 분리
- Hidden Layer 구성
require(mxnet)
my_input = mx.symbol.Variable('data')
fc1 = mx.symbol.FullyConnected(data=my_input, num.hidden = 200, name='fc1')
200개의 뉴런 형성
4개의 input 뉴런과 모두 연결되도록 (Sepal.Length, Sepal.Width, Petal.Length, Petal.Width)
relu1 = mx.symbol.Activation(data=fc1, act.type='relu', name='relu1')
Sigmoid Function 대신 ReLU Function 사용

fc2 = mx.symbol.FullyConnected(data=relu1, num.hidden = 100, name='fc2')
100개의 뉴런 형성
첫번째 Layer의 200개의 뉴런과 모두 연결
relu2 = mx.symbol.Activation(data=fc2, act.type='relu', name='relu2')
- Output Layer 구성
fc3 = mx.symbol.FullyConnected(data=relu2, num.hidden = 3, name='fc3')
3개로 분류(0,1,2)해야하므로 3개의 Output 뉴런을 생성
softmax = mx.symbol.SoftmaxOutput(data=fc3, name='sm')
Softmax의 결과를 통해 가장 큰 값을 선택

5) Neural Network 모델 학습
- 모델 학습
앞에서 만든 Layer르르 이용해서 모델을 형성 및 학습
mx.set.seed(123)
device <- mx.cpu()
model <- mx.model.FeedForward.create(softmax,
optimizer = "sgd",
array.batch.size=25,
num.round = 500, learning.rate=0.1,
X=train_feature, y=trainLabels, ctx=device,
eval.metric = mx.metric.accuracy,
array.layout = "rowmajor",
epoch.end.callback=mx.callback.log.train.metric(100))
Stochastic Gradient Descent
batch size = 10 (총 10개 그룹)
Iteration(epoch) : 300
Learning Step : 0.1

graph.viz(model$symbol)
6) Neural Network 모형- 검증데이터 결과
- 모델 테스트
predict_probs <- predict(model, test_feature, array.layout = "rowmajor")
predicted_labels <- max.col(t(predict_probs)) - 1
table(testLabels, predicted_labels)
sum(diag(table(testLabels, predicted_labels)))/length(predicted_labels)

'공부 > R & Python' 카테고리의 다른 글
| 16-3. 웹문서 텍스트마이닝 - 한글 웹문서의 자연어 처리와 정보 추출 - (0) | 2020.03.06 |
|---|---|
| 16-2. Convolutional Neural Network (0) | 2020.03.06 |
| 15-3. Partial Least Square (0) | 2020.03.06 |
| 15-2. 주성분 회귀분석(Principle Component Regression) (0) | 2020.03.06 |
| 15-1. 주성분 분석과 부분 최소자승법-주성분분석(Principle Component Analysis) (0) | 2020.03.06 |



