9-3. 데이터마이닝과 분류 (분류규칙과 과적합)
2) 분류 (Classification)
- 분류분석 (classification analysis)은 다수의 속성 (attribute)을 갖는 객체 (object)를 그룹 또는 범주 (class, category) 로 분류
- 학습표본 (training sample)으로부터 효율적인 분류규칙 (classification rule)을 생성
오분류율 최소화 (cost function을 최소화)

- 분류규칙
이동통신회사 선호도 조사 (n=9), 타켓변수(선호통신사)=A, B
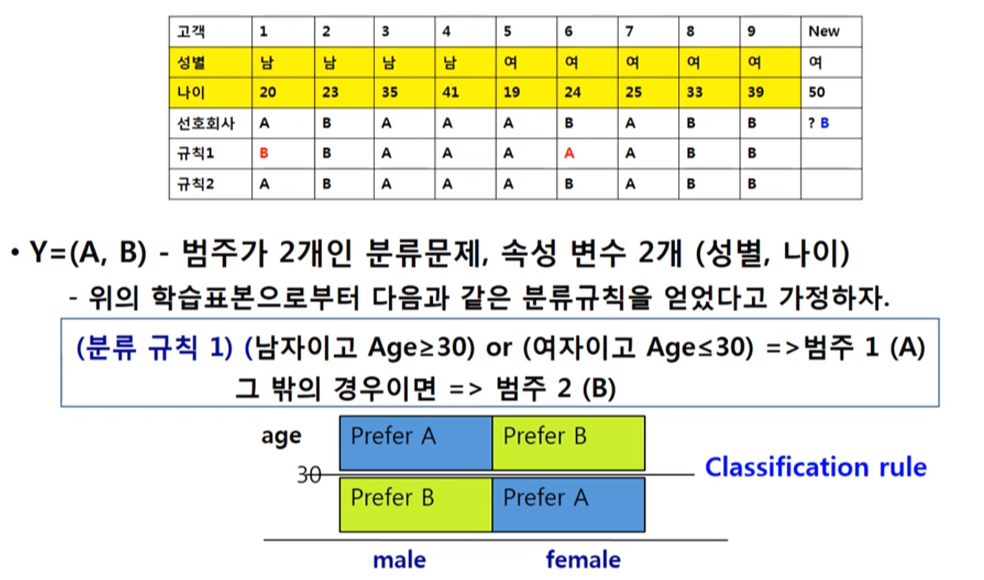
- 오분류율(Misclassification rate)
오분류율 = 오분류 객체수/전체 객체수 = 2/9 = 0.22
- 과적합(overfitting)
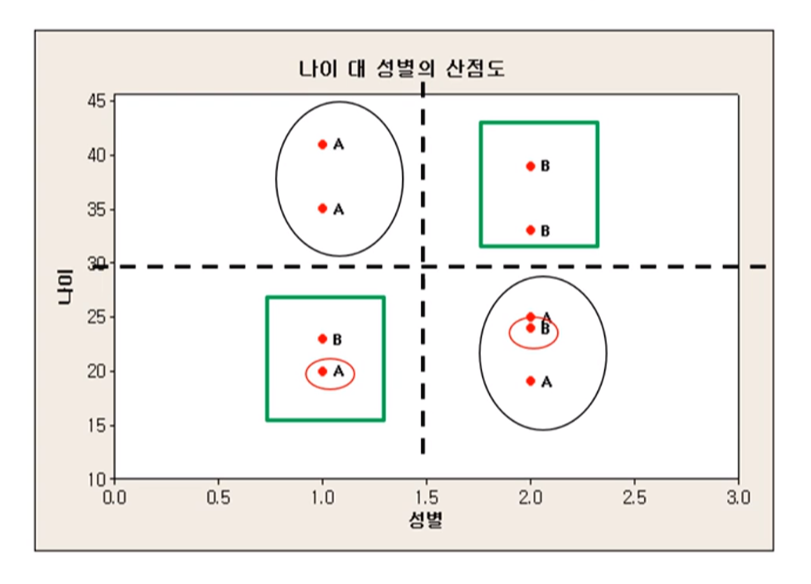
앞의 분류문제에 대해서 (분류규칙 2)
(분류규칙 2) [남자 & (Age>=30 or Age<=20) ] => 범주 1 (A)
그 밖의 경우이면 => 범주 2 (B) (단, 여자이고 나이가 24이면 범주 2)
(분류규칙 2)에 따르면 오분류율 0/9=0이 된다. 학습표본에 대해서 오분류율을 0으로 인위적으로 만드는 경우 과적합 (overfitting)이라고 한다
과적합 (overfitting)
분류모형에서 훈련데이터에 대한 과적합을 시킬 경우, 실제 데이터를 적용했을때 더 높은 오분류율 발생
- 예측모형에서의 과적합
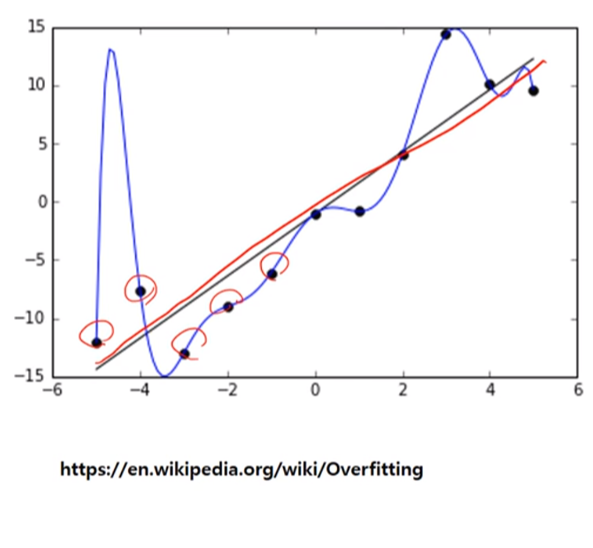
예측모형에서 훈련데이터에 대한 과한 적합모델을 선택하는 경우, 실제 데이터를 적용했을 때 더 높은 오차를 발생
=> 이런 과적합 문제를 방지하기 위하여 학습데이터와 검증데이터를 5:5, 6:4, 7:3, 8:2 로 분리하여 모형의 성능을 비교 평가한다
학습데이터 (70%) 검증데이터 (30%)
- 분류모형의 유효성 검증방법
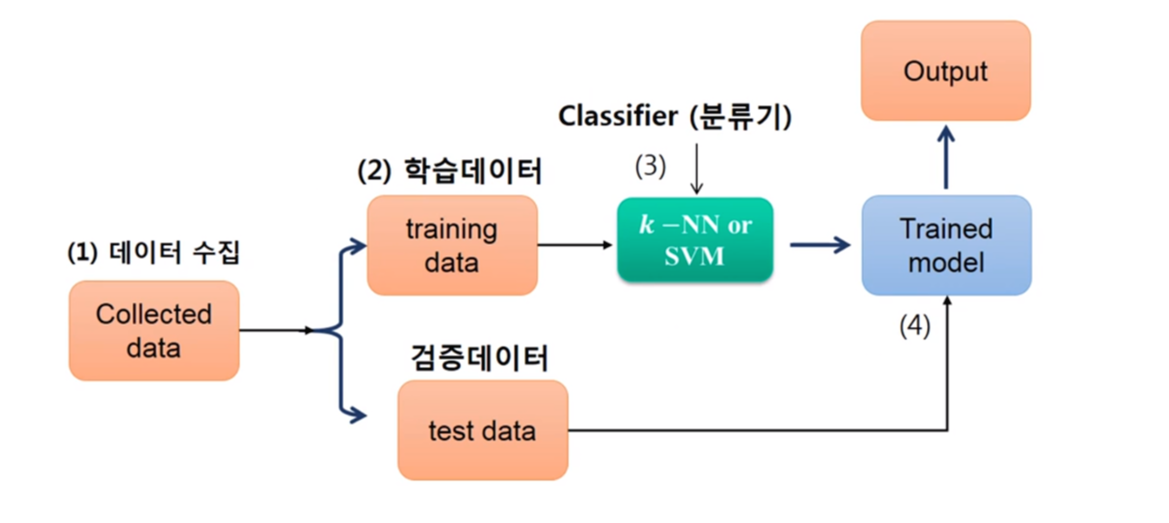
- 교차검증(cross-validation)
k-fold cross validation method 교차타당성 검증
5-fold cross-calidation의 예제 : n=100 이면 5등분으로 나누어 4등분은 학습데이터로 예측 모형을 구성하고, 나머지 5등분째 데이터로 검증한다
'공부 > R & Python' 카테고리의 다른 글
| 10-1. k-인접기법과 판별분석-k-인접기법(k-Nearest Neighbor) (0) | 2020.02.26 |
|---|---|
| 9-4. 데이터마이닝과 분류 (학습데이터와 검증데이터) (0) | 2020.02.24 |
| 9-2. 데이터마이닝과 예측 (다중회귀분석2) (0) | 2020.02.18 |
| 9-1. 데이터 마이닝 기초-데이터마이닝과 예측 (다중회귀분석1) (0) | 2020.02.17 |
| 8-4. 텍스트마이닝2 (0) | 2020.02.17 |



