Sora: 콘텐츠 제작의 미래를 선도하는 비디오 생성 모델

지난 15일(현지 시각), OpenAI는 Text-to-Video 생성 모델 ‘소라(Sora)’를 홈페이지에 공개했습니다.
OpenAI의 Sora는 텍스트 기반의 입력에서 비디오를 생성하여 창작의 새로운 장을 열 것으로 기대됩니다.
Sora: Creating video from text
The current model has weaknesses. It may struggle with accurately simulating the physics of a complex scene, and may not understand specific instances of cause and effect. For example, a person might take a bite out of a cookie, but afterward, the cookie m
openai.com
목차
Sora란?
Sora의 특징
Sora의 작동 원리
Sora의 한계
Sora 기술보고서
Sora 기대효과
1. Sora란?
Sora는 사용자가 입력한 텍스트 설명을 바탕으로 복잡한 비디오 시나리오를 자동으로 생성할 수 있는 OpenAI의 최신 AI 모델입니다. 이미지, 사운드, 움직임을 포함한 비디오를 단순한 텍스트에서부터 생성해내어 다양한 분야에서의 활용 가능할 것으로 보입니다.
2. Sora의 특징
- 복잡한 시나리오 생성: 다양한 등장인물과 배경, 움직임을 포함한 복잡한 비디오 시나리오를 생성할 수 있습니다
- 번역 프롬프트: 애니메이션 장면은 녹고 있는 빨간 촛불 옆에 무릎을 꿇고 있는 짧고 푹신한 괴물의 클로즈업을 특징으로 합니다. 예술 스타일은 3D이며 현실적이고, 조명과 질감에 초점을 맞추고 있습니다. 그림의 분위기는 괴물이 눈을 크게 뜨고 입을 벌린 채 불꽃을 바라보며 경이와 호기심의 느낌을 줍니다. 그것의 포즈와 표정은 마치 처음으로 주변 세계를 탐험하는 것처럼 순수함과 장난기를 전달합니다. 따뜻한 색상과 극적인 조명의 사용은 이미지의 아늑한 분위기를 더욱 강조합니다.
- 원본 프롬프트
- 더보기
Prompt: Animated scene features a close-up of a short fluffy monster kneeling beside a melting red candle. The art style is 3D and realistic, with a focus on lighting and texture. The mood of the painting is one of wonder and curiosity, as the monster gazes at the flame with wide eyes and open mouth. Its pose and expression convey a sense of innocence and playfulness, as if it is exploring the world around it for the first time. The use of warm colors and dramatic lighting further enhances the cozy atmosphere of the image.
- 고화질 비디오 생성: 1080p까지의 고화질 비디오를 생성, 창의적인 작업에 높은 퀄리티를 제공합니다.
- 번역 프롬프트: 스타일리시한 여성이 따뜻한 네온 불빛과 애니메이션 도시 간판으로 가득 찬 도쿄의 거리를 걷습니다. 그녀는 검은 가죽 재킷, 긴 빨간 드레스, 검은 부츠를 착용하고 있으며, 검은색 핸드백을 들고 있습니다. 그녀는 선글라스와 빨간 립스틱을 바르고 있습니다. 그녀는 자신감 있고 느긋하게 걷습니다. 거리는 축축하고 반사적이어서, 다채로운 불빛의 거울 효과를 만들어냅니다. 많은 보행자들이 거닐고 있습니다.
- 원본 프롬프트
더보기Prompt: A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.
- 번역 프롬프트: 스타일리시한 여성이 따뜻한 네온 불빛과 애니메이션 도시 간판으로 가득 찬 도쿄의 거리를 걷습니다. 그녀는 검은 가죽 재킷, 긴 빨간 드레스, 검은 부츠를 착용하고 있으며, 검은색 핸드백을 들고 있습니다. 그녀는 선글라스와 빨간 립스틱을 바르고 있습니다. 그녀는 자신감 있고 느긋하게 걷습니다. 거리는 축축하고 반사적이어서, 다채로운 불빛의 거울 효과를 만들어냅니다. 많은 보행자들이 거닐고 있습니다.
- 창작의 새로운 가능성: 기존에는 구현하기 어려웠던 아이디어나 시나리오를 실제 비디오로 실현할 수 있게 해줍니다.
3. Sora의 작동 원리
Diffusion Model
Sora는 이미지 생성에 사용되는 DALL-E 3와 같은 기술, 즉 확산 모델을 기반으로 합니다. 확산 모델은 무작위 픽셀 배열에서 시작하여 점차적으로 명확한 이미지로 변환하는 방식으로 작동합니다. Sora는 이를 동영상 생성에 적용하여, 시간이 지남에 따라 변화하는 시각적 내용을 생성합니다.
Transformer Architecture
Sora는 트랜스포머 아키텍처를 사용하여 비디오 데이터를 처리합니다. 트랜스포머는 긴 데이터 시퀀스를 효과적으로 처리할 수 있는 신경망 구조로, 주로 텍스트 데이터 처리에 사용됩니다. Sora는 비디오를 시간과 공간에 걸쳐 작은 청크로 분할하고, 이 청크들을 트랜스포머를 통해 처리하여 복잡한 비디오 시퀀스를 생성합니다.
Recaptioning Technique
Sora는 사용자의 프롬프트에서 출발하여, 더욱 상세하게 서술하는 방식으로 작동합니다. DALL-E 3에서 도입된 기술과 동일하며, 생성된 콘텐츠의 품질을 향상시킵니다.
4. Sora의 한계
실제 세계의 물리학과의 차이
현재 Sora는 실제 세계의 물리학을 완벽하게 이해하거나 반영하지 못하는 경우가 있습니다. 다음 사례에서, Sora는 의자를 강체로 모델링하는 데 실패하여, 부정확한 물리적 상호작용을 보여줍니다.
- 번역 프롬프트: 고고학자들이 사막에서 일반적인 플라스틱 의자를 발견하여, 매우 세심하게 발굴하고 먼지를 털어냅니다.
- 원본 프롬프트
- 더보기
Prompt: Archeologists discover a generic plastic chair in the desert, excavating and dusting it with great care.
시공간적 세부사항 혼동
모델은 또한 프롬프트의 공간적 세부 사항을 혼동할 수 있습니다. 예를 들어, 왼쪽과 오른쪽을 혼동하거나, 특정 카메라 궤적을 따르는 것처럼 시간에 걸쳐 일어나는 사건을 정확히 설명하는 것에 어려움을 겪을 수 있습니다.
5. Sora 기술보고서
Video generation models as world simulators(세계 시뮬레이터로서의 비디오 생성 모델)
https://openai.com/research/video-generation-models-as-world-simulators
Video generation models as world simulators
We explore large-scale training of generative models on video data. Specifically, we train text-conditional diffusion models jointly on videos and images of variable durations, resolutions and aspect ratios. We leverage a transformer architecture that oper
openai.com
시각적 데이터의 다양성을 통합적으로 표현하고, 생성 모델의 성능을 극대화하는 방법을 다룹니다.
Turning visual data into patches & Spacetime latent patches
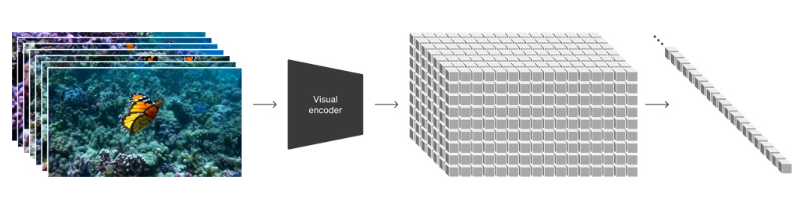
대규모 언어 모델(LLM)에서 영감을 받아, Sora는 시각적 ' patches(패치)'를 사용하여 비디오 및 이미지 데이터를 효과적으로 표현합니다. 패치 기반 표현은 다양한 해상도, 지속 시간, 종횡비를 가진 시각적 데이터에 대한 범용적인 모델 훈련을 가능하게 합니다.
Video compression network & Scaling transformers for video generation

비디오 데이터를 낮은 차원의 잠재 공간으로 압축하고, 이를 시공간 패치로 분해하여 처리하는 방식을 통해, Sora는 고품질의 비디오 생성을 실현합니다. 여기서 확산 모델 기반의 변환기는 잡음(noisy)이 섞인 패치로부터 원본 'clean(깨끗한)' 패치를 예측합니다.
Variable durations, resolutions, aspect ratios
- Sampling flexibility & Improved framing and composition
Sora는 다양한 종횡비와 해상도를 가진 비디오를 생성할 수 있으며, 이는 다양한 디바이스와 사용 사례에 맞춤화된 콘텐츠 생성을 가능하게 합니다.
Language understanding
DALL·E 3의 re-captioning 기법을 활용하여 사용자 프롬프트를 자세한 캡션으로 변환(descriptive captioner 모델 학습)하고, 이를 통해 사용자의 지시에 정확히 부합하는 고품질 비디오를 생성합니다.
그 외에도 Sora는 이미지 및 비디오 프롬프트를 사용하여 다양한 이미지 및 비디오 편집 작업을 수행할 수 있으며, 이는 정적 이미지의 애니메이션화, 비디오의 시간적 확장 등을 포함합니다.
6. Sora 기대효과
- 콘텐츠 제작 산업
많은 시간과 비용 없이 아이디어와 스토리를 시각화할 수 있는 효과적인 도구를 제공하여, 영화 제작자, 콘텐츠 제작자, 예술가들에게 새로운 창작의 가능성을 열어줄 것으로 보입니다.
- 교육 산업
교육 환경에서 Sora가 학습자들에게 상호 작용이 가능한 자료를 제공함으로써, 복잡한 주제를 시각적으로 표현하여 더 쉽게 이해할 수 있게 도와줄 수 있을 것으로 생각됩니다.
- 윤리적 문제
생성 모델은 윤리적으로 부적절하거나 허위 사실을 전달하는 콘텐츠를 생성할 수 있습니다. 이와 관련하여 Open AI에서는 현재 배포 전 내부 안전 테스트를 진행하고 있습니다.
'IT > 인공지능' 카테고리의 다른 글
| [생성형AI][LLM] RAG 기반 기술문서 QA Gemma 모델 (Hugging Face) (0) | 2024.02.24 |
|---|---|
| [생성형AI][LLM] Gemma 모델 파인튜닝 (Hugging Face) (3) | 2024.02.24 |
| [생성형AI][RAG] 증상 기반 법정감염병 판별 챗봇 (0) | 2024.02.09 |
| [생성형AI][LLM] 데이터 없이 생성형 AI를 활용하여 개체명인식(NER) 분류 - 금융 도메인 (4) | 2024.02.07 |
| [언어모델 변천사 A to Z] RNN부터 GPT까지 가볍게 살펴보기 (0) | 2023.03.25 |

